XPathOnUrl
=XPathOnUrl(
string url,
string xpath,
string attribute,
string xmlHttpSettings,
string mode
) : vector
Purpose
Fetches url and returns the (array) result from XPath expression.
You can use XPathOnUrl on any XML resource.
Xpath
XPath queries has to be in lower case. So /HTML/BODY/A won't work.
Attribute (optional)
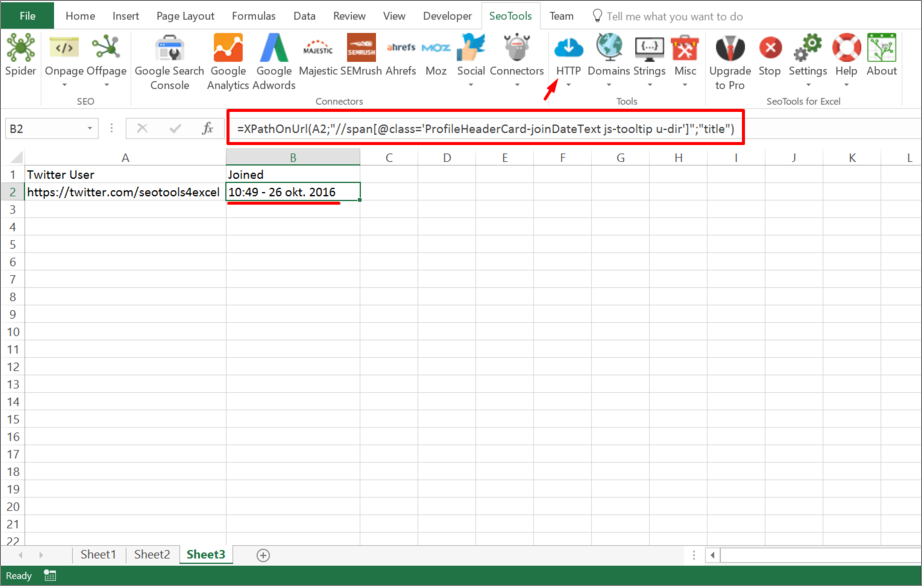
The optional attribute allows you to retreive the value of an attribute of the specified node. Xpath /foo/@bar returns the inner text of node foo. To get attribute bar you specify:
=XPathOnUrl(url,"/foo","bar")
XmlHttpSettings (optional)
You can control the HTTP request (such as header and form variables) using the xmlHttpSettings. See HttpSettings.
Mode (optional)
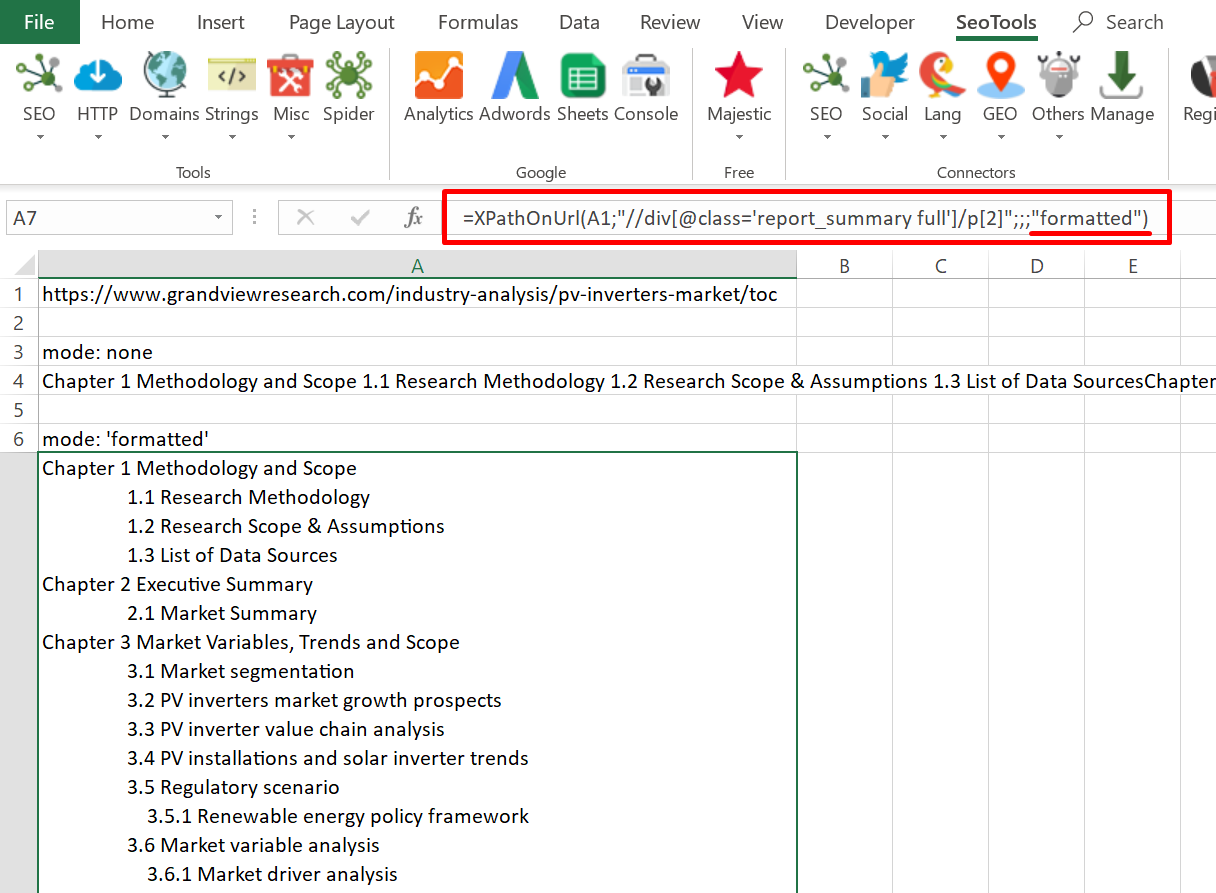
The output can be extracted in raw HTML format or "formatted":
=XPathOnUrl(url,"//div[1]",,,"html")
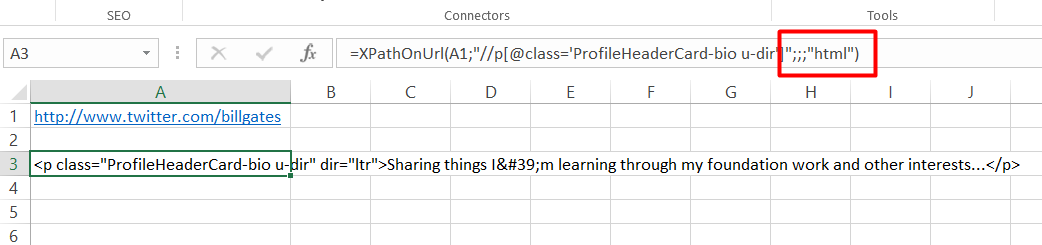
=XPathOnUrl(url,"//div[1]",,,"formatted")
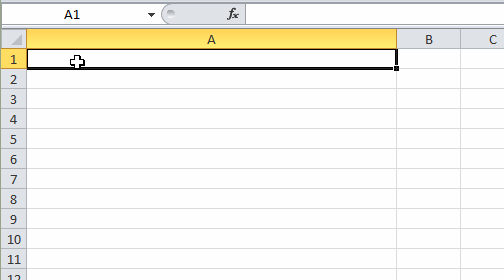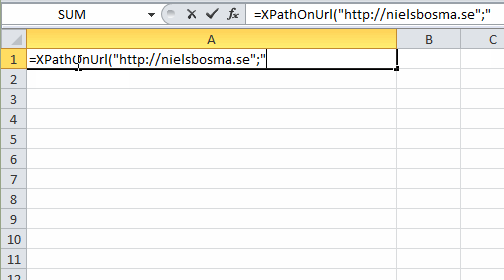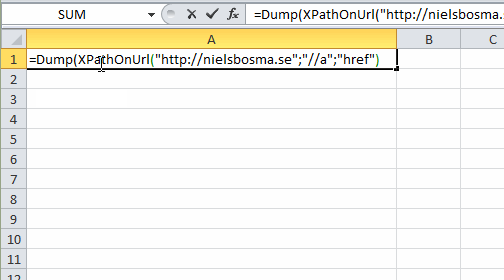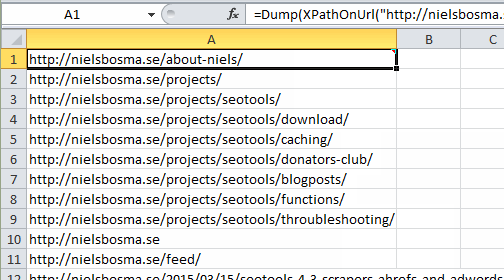
Dump
Fetches the url and returns the (vector) result from xpath expression.
Local files
You can also parse local files using XPathOnUrl using either absolute or relative (to spreadsheet) filepaths:
file:///C:\path\to\file.xml
file:///path\relative\workbook.xml
file:///..\..\path\relative\workbook.xml
See: DirectoryList
Examples
Return number of nodes
Retreive the number of links on a page:
=XPathOnUrl("https://seotoolsforexcel.com/","count(//a)")
Alternative to Dump
=XPathOnUrl("https://www.google.com/search?
q=dogs","(//h3[@class='r']/a)[1]","href")
This will reference the first node. To get all results in a column, you first create a column (in say column A) with values 1..10 and use the following formula:
=XPathOnUrl("https://www.google.com/search?q=dogs"
,"(//h3[@class='r']/a)["&A1&"]","href")
Get help with this function in the community →